Data Handling aka Duplicated Entries in Raw Data Table
We always wanted to not bother you with Exply's internal data handling. But over the last 10 years of development we've come to the point that it is necessary. So, here we go.
Exply uses ElasticSearch as a database. You can think of it as a large Excel spreadsheet into which all the data is written. This reduces the response times to a fraction of the normal database queries. But, this also comes with a small downside.
Exply needs to use multiple data types (issues, time records, etc.) to represent hierarchy logic, for example. This can lead to unwanted side effects like mentioned in the headline.
For instance, you want to create a table that shows all issues. When using the Raw Data Table widget you most certainly end up with a list of issues and some of them show up more than once (see example below).
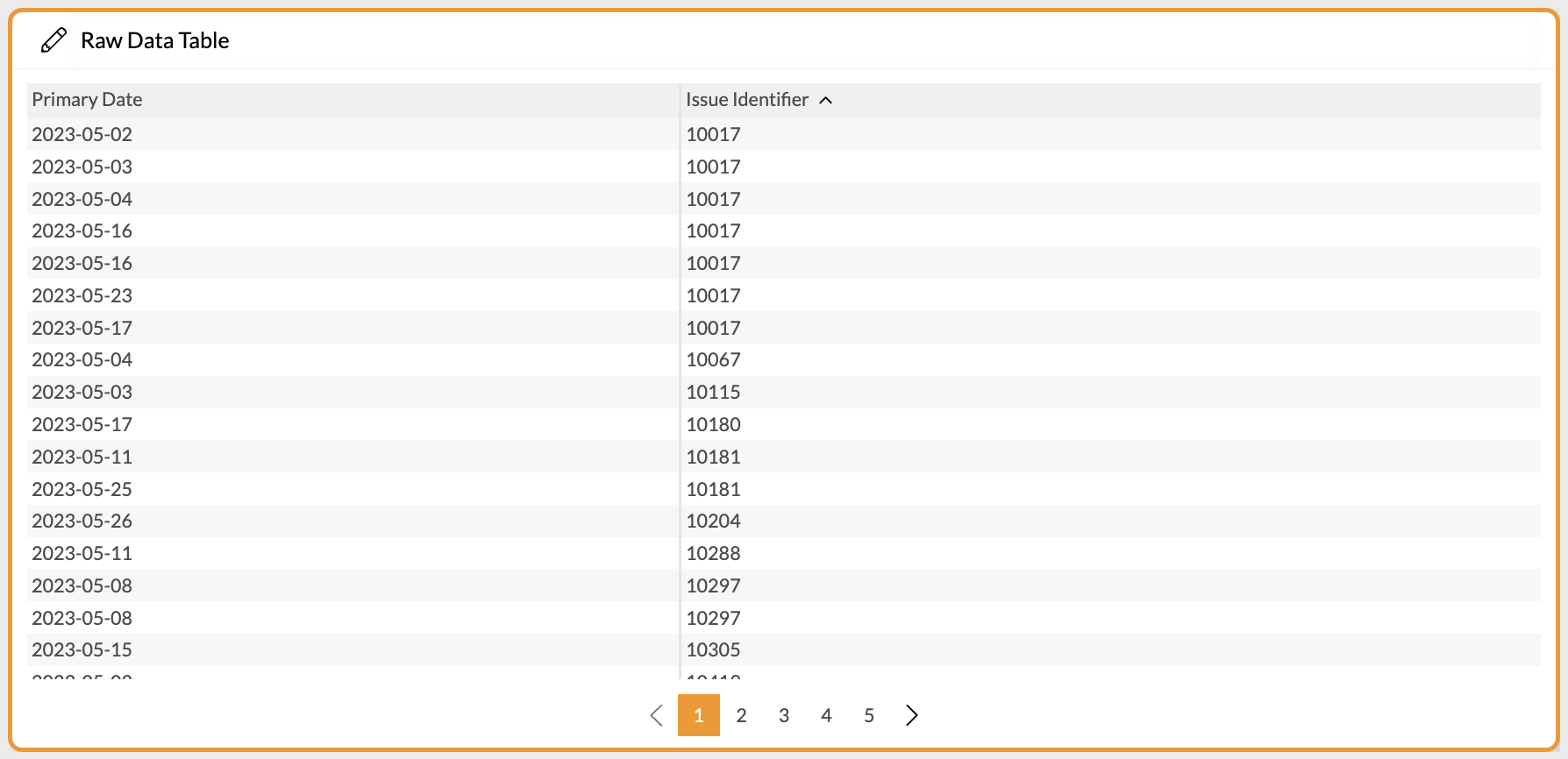
Raw Data Table showing duplicate Issues, e.g. "10017"
This is due to the way Exply is handling the imported data. So, if you want to see issues and select the corresponding data field to show in the table every data point is shown that contains a "reference" to the issue. This most often applies to time entries, for instance like in the example below:
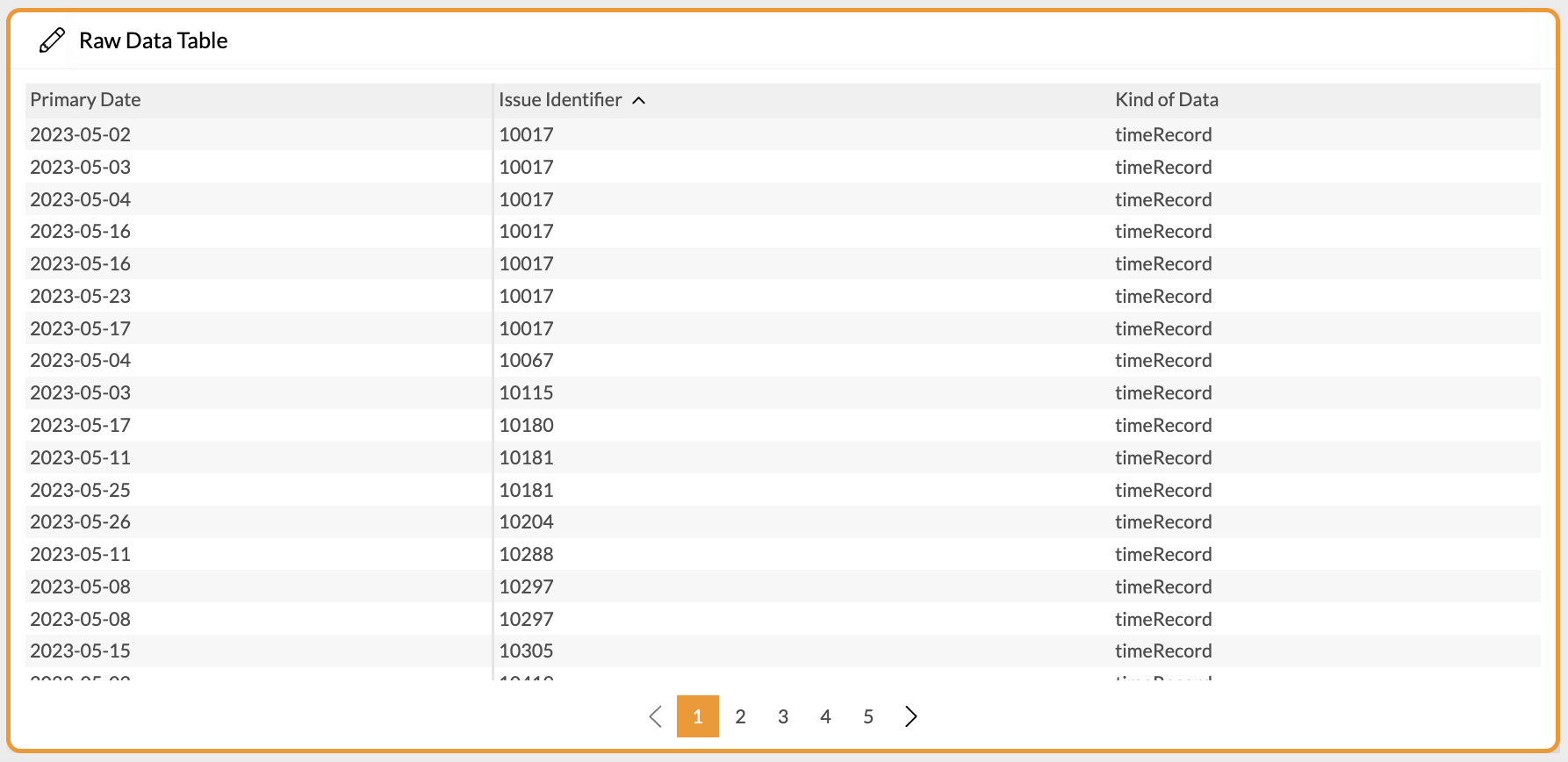
Raw Data Table Duplicate Issues with Data Types
The solution to this is that you set a filter on the data type you want - in our case this should probably be "Task". You can set the filter specifically per Value, Widget, or per Dashboard Group, Dashboard - depending on how far you want the filter to apply. Attached is an example:
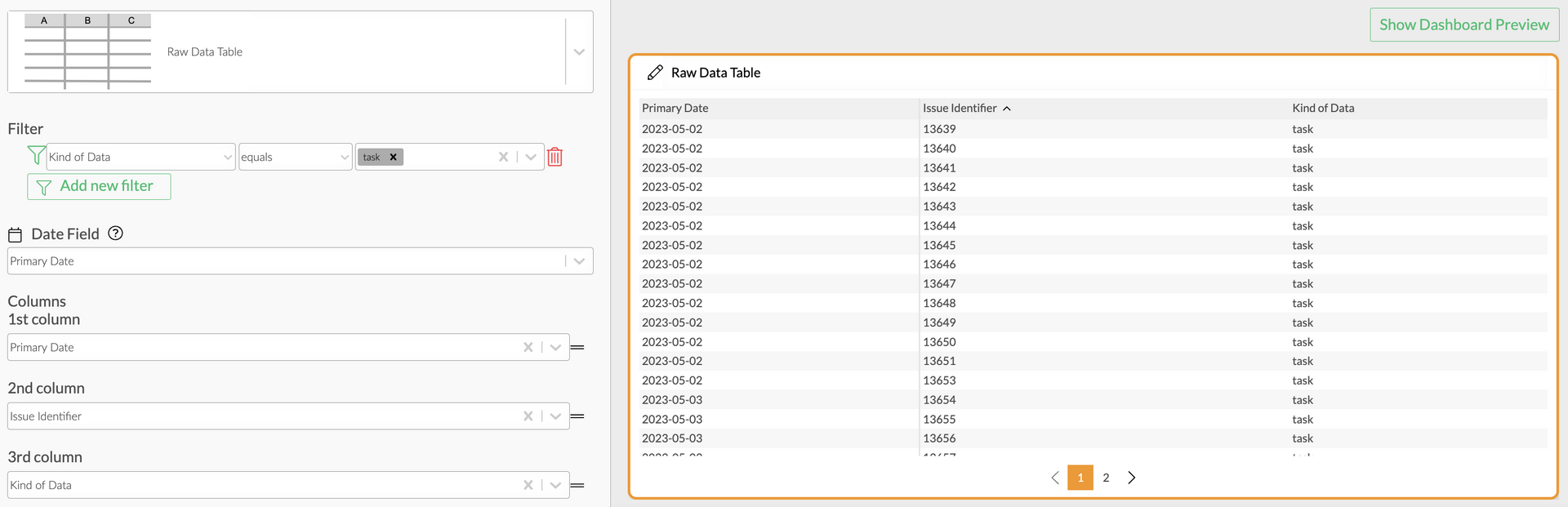
Raw Data Table Duplicate Issues with data types and filter set to "Task"